Clustering With User Feedback
This post is based on the following publications:
- COBRAS: Interactive clustering with pairwise constraints. Van Craenendonck, T., Dumancic, S., Vanwolputte, E. & Blockeel, H. Intelligent Data Analysis, 2018.
- Tackling noise in active semi-supervised clustering. Soenen, J., Dumancic, S., Van Craenendonck, T., Blockeel, H. European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2020.
Software is available in the following toolboxes: COBRAS and nCOBRAS
Data analysts often try to make sense of data by clustering it. This means they try to identify groups of objects that are somehow very similar and “belong together”. For instance, this is what biologists have done for ages when they categorize animals and plants: they identify, say, felines, as a set of animals with certain characteristics, which can be further subdivided into lions, tigers, leopards, etc. Similarly, one could cluster movies according to their genre: western, science fiction, etc. This is a task that service providers such as Netflix are interested in — understanding clusters helps them make better recommendations to customers!
But objects can often be clustered in different ways. Movies could be considered “similar” when they fit in the same genre, but also, when they are from the same director, share important actors, etc. So when we say “similar” objects should be clustered together, we first need to be precise about what “similar” means. Once that is done, a computer program can cluster the data for us. But how do you explain to a computer what you consider similar?
Traditionally, the user needs to provide a mathematical formula that expresses similarity. But it is often very hard for users to provide such a formula or algorithm. And that’s not the only problem. Even for a fixed similarity measure, different clustering algorithms may return different clusterings. Moreover, algorithms for clustering have so-called hyperparameters, which can be set by the user and which change their behavior. So, to obtain a good clustering, a user needs to get at least 3 things right: the similarity measure, the clustering algorithm, and it hyperparameter settings. Often, this requires a lot of trial and error and a good understanding of how clustering works.
Our research focuses on how to make it easier for users to get the clusters they want. We achieve this through active, semi-supervised, robust clustering.
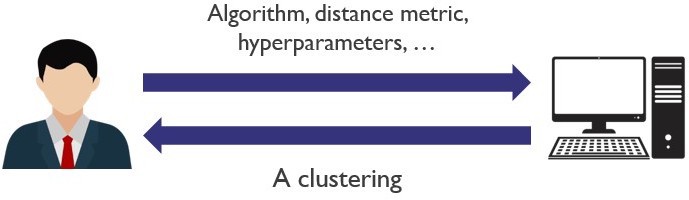
Semi-supervised learning
To avoid having to go through the process of finetuning the distance metric, algorithm and hyperparameters, some clustering algorithms allow to simply provide some example pairs of objects that belong in the same cluster and some pairs of objects that belong in different clusters.
In the literature, these example pairs are often referred to as constraints: a must-link constraint between objects reflects that the two involved objects must be in the same cluster, a cannot-link constraint reflects that the two involved objects must be in different clusters.
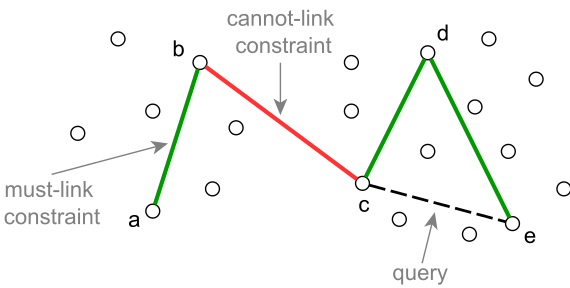
Active learning
Not all examples a user provides are equally informative. Some of the provided examples might be useless for the algorithm. To minimize the effort the user needs to spent labelling, it is better to let the algorithm decide which pairs of instances the user should label. This way, the algorithm can query the most informative object pairs first and produce a high-quality clustering with a low amount of effort from the user. Concretely, the algorithm will ask the user: “Should object x and object y be in the same cluster or not?”. Answering with “yes” results in a must-link constraint between the objects, while answering with “no” results in a cannot-link constraint. This setting is called active semi-supervised clustering.

For more on how COBRAS can be used to cluster timeseries see Time Series Clustering.)
User mistakes in active semi-supervised clustering
Asking the user questions is a good way to gather informative constraints from the user. However, a user might also make mistakes when answering the queries. Most semi-supervised clustering algorithms assume that all answers are correct. In these algorithms, a single user mistake can have a detrimental impact on the quality of the produced clustering.
nCOBRAS is a modification of COBRAS where this noise correcting mechanism is added. This mechanism makes COBRAS significantly more robust to mistakes from the user at the cost of a few additional redundant constraints. Extensive experiments show that, in the presence of noise, nCOBRAS produces on average higher quality clusterings than COBRAS for the same number of queries.
Jonas Soenen
PhD student
My research interests include active and semi-supervised learning applied to usually unsupervised problems such as clustering and anomaly detection.
Hendrik Blockeel
Full professor
Theory and algorithms for machine learning and data mining in general.